Dans une ère où l’automatisation et la précision sont primordiales, l’intelligence artificielle (IA) joue un rôle crucial. Un des champs d’application les plus fascinants de l’IA est la vision par ordinateur, qui permet à une machine de « voir » et d’interpréter des images et des vidéos, tout comme le ferait un œil humain. Mais pourquoi serait-ce utile?
Un œil sur la production
Imaginez une chaîne de production où des milliers d’articles défilent chaque minute. La rapidité est un atout, mais elle ne doit pas compromettre la qualité. Comment s’assurer que chaque pièce produite respecte les normes? C’est là qu’intervient la classification d’images. Un système équipé de caméras et d’IA peut instantanément inspecter chaque article et le classer comme « conforme » ou « défectueux ». En identifiant une anomalie, même minime, la chaîne peut être alertée pour rectifier le tir ou mettre de côté la pièce défectueuse.
Et si on identifiait nos citrouilles pour Halloween
La classification d’images ne se limite pas aux usines. Prenons un exemple de saison. Nous sommes en octobre, le mois des citrouilles!
Certaines sont parfaites pour faire une soupe ou une tarte, tandis que d’autres sont sculptées en Jack O’Lantern pour Halloween !
Imaginez un fermier qui souhaite séparer automatiquement les citrouilles destinées à la cuisine de celles destinées à la décoration. Une caméra, associée à un algorithme de classification, pourrait facilement effectuer cette tâche, gagnant du temps et assurant la satisfaction des clients.
Mais comment cela fonctionne-t-il concrètement? Plongeons dans le vif du sujet!
Comment classer des images avec l’intelligence artificielle ?
L’intelligence artificielle (IA) a fait d’énormes progrès ces dernières années, notamment dans le domaine de la vision par ordinateur. Un des usages populaires de la vision par ordinateur est la classification d’images. Dans cet article, nous verrons comment, avec quelques lignes de code, il est possible de créer un système qui peut différencier des images de catégories différentes, par exemple des citrouilles et des Jack O’Lanterns.
Étape 1 : Préparation des données
Avant de plonger dans la construction du modèle, il est essentiel de préparer les données. Pour notre exemple, supposons que nous ayons deux dossiers d’images : l’un contenant des photos de citrouilles et l’autre des photos de Jack O’Lanterns.
Ces images nous servirons pour entrainer le modèle. Les données sont étiquetée pour un apprentissage supervisé.
Pour en savoir plus sur l’apprentissage je vous invite à lire cet article Apprentissage automatique.
dir1 = "photos_citrouille"dir2 = "photos_jack"



Je vais vectoriser les images. Ainsi le modèle va pouvoir s’entrainer. Vous pouvez constater dans cette vidéo que les images de citrouilles et de Jack O’Lantern ne sont pas vectorisées dans le même espace. Ce qui va permettre au modèle de classification de distinguer les deux types d’images.
Étape 2 : Traitement des images
Les images, généralement de différentes tailles et couleurs, doivent être uniformisées pour être traitées par le modèle. Pour cet exemple, je décide de réduire la taille des images en 64 pixels de coté, toutes les images seront en couleurs RGB (Rouge, Vert, Bleu).
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = cv2.resize(img, (64, 64))Étape 3 : Création du modèle
L’étape suivante consiste à définir notre modèle d’IA. Pour cet exemple, nous utiliserons un modèle simple avec une seule couche entièrement connectée.
Notre problème étant relativement simple, avec une solution binaire : Citrouille ou Jack O’Lantern , un neurone artificiel sera suffisant. En entrée nous utiliserons une image aplatie (dimensions réduite) avec 64*64 pixels multipliés par les 3 couleurs. La fonction d’activation sera Sigmoïd.
model = tf.keras.models.Sequential([
tf.keras.layers.Input(shape=(64*64*3,)),
tf.keras.layers.Dense(1, activation='sigmoid')
])Étape 4 : Compilation et Entraînement du modèle
Après avoir défini le modèle, il faut le compiler et le former à reconnaître les différences entre les deux types d’images. Nous utiliserons un fonction d’optimisation « Adam » et une fonction de perte « binary_crossentropy » car, comme vu précédemment, notre solution doit être binaire.
Nous nous limiterons à 10 passes d’entrainement.
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
history = model.fit(X_train, y_train, epochs=10, validation_data=(X_test, y_test))
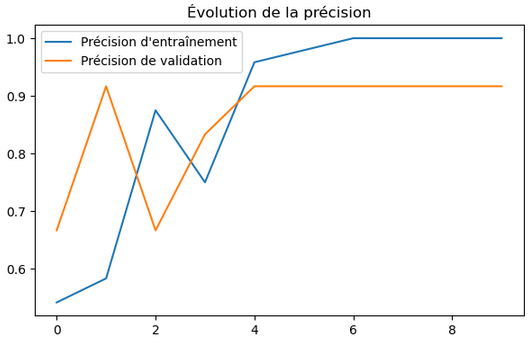
Étape 5 : Prédiction
Une fois le modèle formé, il est temps de l’utiliser pour prédire la catégorie d’une nouvelle image. Et vérifier, que cela fonctionne avec de nouvelles images qui ne faisaient pas partie des images utilisées pour l’entrainement.
Comme on peut le constater, en moins de 17 millisecondes, le modèle arrive à reconnaitre les citrouilles comestibles des Jack O’Lantern !
Notre fermier est prêt pour vendre ses citrouilles aux bons clients.


Si vous souhaitez recevoir la version complète du code python afin de classifier vos images, laissez-moi un commentaire, je vous l’enverrai.