Aujourd’hui, je suis ravi de partager avec vous une aventure passionnante dans le monde de l’intelligence artificielle (IA).
Je vais vous expliquer, de manière conviviale et accessible, comment les réseaux de neurones et un mécanisme fascinant appelé « attention » transforment les données en prédictions étonnantes. Pas besoin d’être un pro de l’informatique pour suivre ; embarquons ensemble dans cette exploration !
Le réseau et les étapes ont été réalisées sont mon projet d’analyse des pertes du nombre de commandes dans une pizzeria dont voici le lien
Les réseaux de neurones : comme un puzzle multidimensionnel
Imaginez un puzzle en 3D complexe à résoudre. Un réseau de neurone est un programme composé d’unités (ou neurones) , ou chacune de ses unités va se spécialiser durant une phase d’entrainement à identifier certaines pièces des puzzles qu’on lui présente.
Dans le programme, on organise les neurones en équipes successives qu’on appelle couches. Quand je nourris le réseau avec des données, les données passent au travers des couches successives, chacune apportant sa pièce au puzzle, pour former une image complète et compréhensible.

Le mécanisme d’attention
Au sein de ce réseau, une vedette émerge : le mécanisme d’attention. Imaginez que vous lisez un article et que certains mots ou phrases sont plus importants pour comprendre l’histoire, vous allez peut-être les surligner ou vous concentrer plus dessus (comme ici avec du texte en gras).
Le mécanisme d’attention dans l’IA fonctionne de manière similaire, en se concentrant sur les parties les plus informatives des données pour améliorer la qualité des prédictions. .
J’ai intégré une couche d’attention dans mon modèle pour améliorer la capacité du modèle à se concentrer sur les parties les plus pertinentes des données.
Cette couche crée un vecteur de poids, qui est appliqué aux données pour amplifier l’importance de certaines caractéristiques tout en en réduisant d’autres.
Le vecteur de poids est obtenu en utilisant une combinaison de transformations mathématiques (comme tanh et softmax) sur les données.
Construire le modèle
La construction du modèle est comme assembler des lasagnes en cuisine. Chaque couche doit être choisi et combiné de manière stratégique.
Voici le bout de code correspondant au modèle:
model = keras.Sequential([
layers.Input(shape=(X_train.shape[1],)),
layers.Dense(16, activation='relu'),
layers.Dense(16, activation='relu'),
AttentionLayer(),
layers.Dense(16, activation='relu'),
layers.Dense(16, activation='relu'),
layers.Dense(4, activation='relu'),
layers.Dense(1)
])Dans mon modèle, j’utilise des couches denses (Dense), qui sont des couches de 16 neurones où chaque neurone est connecté à tous les neurones de la couche précédente. Ces couches sont essentielles pour apprendre des modèles complexes à partir des données. La couche d’activation est une « relu » ici.
Dans notre recette, au milieu j’ai ajouté une couche d’attention, qui aide le modèle à se concentrer sur ce qui compte vraiment.
En entrée mon modèle va lire des données : jour de la semaine, mois, température, humidité, s’il pleut, s’il y a un match de foot, si la France joue…
En sortie, le modèle prédit, en fonction des informations qu’il a et et des données d’entrainements qu’il a étudiées, un nombre de pizzas qui seront probablement commandées .
Préparation des données
Avant de plonger dans la formation du modèle, les données doivent être soigneusement préparées. Je ne m’étendrai pas sur cette partie qui est détaillée dans l’article : Comment rebooster une Pizzeria avec l’IA
Toutefois sachez que cela représente au mois 75% du temps du travail (humain).
L’entrainement peut être court ou long en fonction de la quantité d’informations à traiter, de l’algorithme, de votre machine, CPU/GPU…
A titre d’exemple, dans mon exemple, pour analyser 40 paramètres , sur 2 années, avec 100 epochs (passage de l’ensemble des données) et K-Fold (validation croisée) de 5, mon pc avec 16go de mémoire RAM et un CPU standard prend 35 secondes environs.
La validation croisée K-Fold
Dans le monde du deeplearning, deux ans de données quotidiennes c’est relativement peu.
Pour s’assurer que notre modèle est fiable et performant, nous utilisons une technique appelée validation croisée. C’est comme faire passer plusieurs tests à notre modèle pour s’assurer qu’il peut bien prédire dans différentes situations, et pas seulement dans un cas spécifique.
Ici, j’utilise KFold, qui divise les données en un nombre spécifié de segments, forme le modèle sur certains et le teste sur les autres. Cela permet de s’assurer que le modèle fonctionne bien sur divers sous-ensembles des données.
Formation et évaluation
Une fois notre modèle construit, il est temps de l’entrainer avec nos données. C’est un peu comme enseigner à un élève comment résoudre un problème. Après l’entrainement, nous évaluons sa performance en utilisant des métriques spéciales pour voir à quel point il est précis dans ses prédictions.
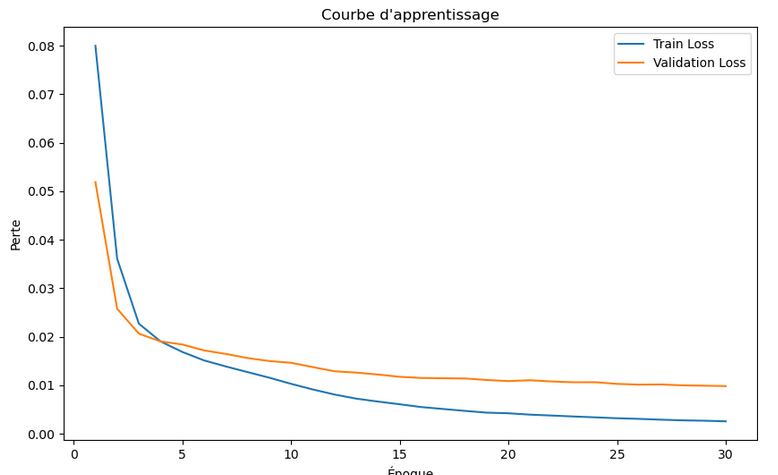
Pour cela, nous utilisons souvent une courbe, dite de perte.
Ce graphique de perte d’entraînement et de validation montrent comment le modèle s’améliore (ou non) au fil des époques, ce qui aide à détecter d’éventuels problèmes comme le sur-ajustement (overfitting).
Voilà ! Vous avez maintenant un aperçu de la manière dont les réseaux de neurones et le mécanisme d’attention aident les IA à transformer des données en prédictions précises. Ce n’est pas seulement de la magie technologique, c’est le résultat d’une ingénierie intelligente et créative. L’IA n’est plus un concept lointain réservé aux scientifiques ; c’est une réalité qui influence déjà notre quotidien de multiples façons. Restez curieux, et qui sait, peut-être que la prochaine fois que vous commanderez une pizza, une IA aura aidé à prédire votre choix !