promesses, réalité technique et nouvelles possibilités
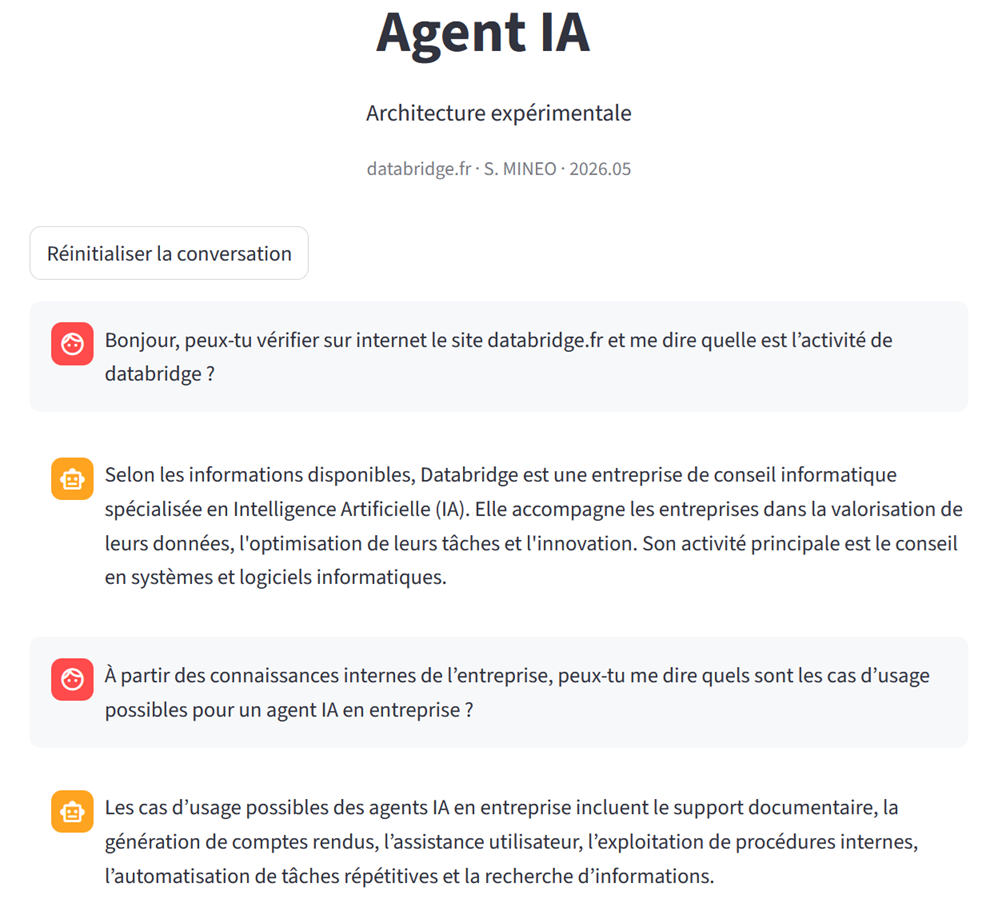
Ce week-end prolongé, j’ai consacré une grande partie de mon temps à finaliser les premiers tests d’un agent IA local capable d’utiliser des outils, manipuler du contexte et exploiter une base de connaissances.
L’objectif était avant tout de comprendre ce qu’il est réellement possible de construire aujourd’hui avec des modèles locaux et une architecture relativement simple.
Pour ce POC, j’ai volontairement choisi de ne pas utiliser de frameworks agentiques existants comme OpenClaw ou d’autres solutions similaires.
Le but n’était pas de réinventer l’existant, mais plutôt de comprendre concrètement les mécanismes réels derrière un agent :
- gestion du contexte,
- sélection des outils,
- orchestration,
- mémoire,
- limitations des modèles et comportements inattendus.
Très rapidement, plusieurs constats sont apparus.
Certaines fonctionnalités semblaient étonnamment efficaces.
D’autres, en revanche, révélaient rapidement certaines limites.
Je vais donc partager ici ce retour d’expérience autour de ce simple POC (Proof of Concept), ainsi que plusieurs problématiques rencontrées lors de ces premières expérimentations.
Des usages très concrets en entreprise
Derrière le terme « agent IA » se cachent surtout de nouveaux usages potentiels pour les entreprises.
Même avec un périmètre encore limité, ce type de système peut déjà permettre :
- de rechercher des informations dans une documentation interne,
- résumer des documents,
- automatiser certaines tâches répétitives,
- assister des utilisateurs,
- centraliser des connaissances,
- faciliter l’accès à certaines données métier.
Dans de nombreux contextes, l’objectif n’est d’ailleurs pas forcément de remplacer un utilisateur humain. L’intérêt peut simplement être de gagner du temps ou répondre à de forte sollicitations. Permettre de concentrer sur le cœur du métier. Améliorer le rendu de certains documents.
C’est précisément ce potentiel qui rend aujourd’hui les systèmes agentiques particulièrement intéressants à explorer pour les entreprises.
Mais au fait, qu’est-ce qu’un agent IA ?
Le terme “agent IA” est aujourd’hui utilisé un peu partout.
Pourtant, derrière ce mot se cachent souvent des réalités très différentes.
Dans sa forme la plus simple, un agent IA peut être vu comme un système capable :
- d’interpréter une demande,
- de choisir une ou plusieurs actions,
- puis d’utiliser différents outils pour atteindre un objectif.
Contrairement à un chatbot classique qui se contente de générer du texte, un agent peut interagir avec son environnement :
- lire un document,
- effectuer une recherche sur internet,
- appeler une API (un service externe),
- exécuter du code,
- ou interroger une base de données.
Finalement, on peut voir un agent comme une IA placée devant plusieurs boutons sur lesquels elle peut décider d’appuyer.
Et c’est précisément là que les choses commencent à devenir intéressantes… et parfois beaucoup plus complexes que prévu.
Une architecture volontairement simple et locale
Pour ces premiers tests, l’objectif n’était pas de construire une plateforme complète, mais plutôt un POC permettant de comprendre les mécanismes fondamentaux derrière un agent IA.
L’architecture retenue reste donc relativement simple :
- un orchestrateur développé en Python,
- plusieurs outils (programmes informatiques) accessibles par l’agent,
- une base de données PostgreSQL pour stocker certaines informations,
- un système de vectorisation pour la recherche sémantique,
- et des modèles de langage exécutés localement via Ollama.
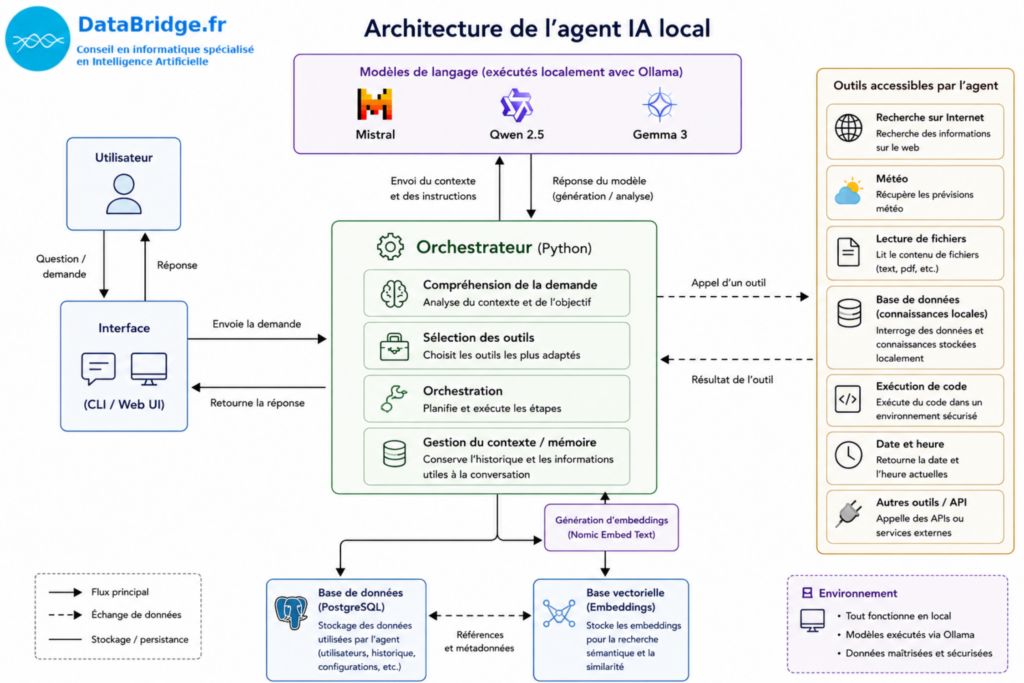
Le choix du local était volontaire.
Aujourd’hui, de nombreuses démonstrations d’agents reposent entièrement sur des APIs cloud ou modèles très puissants.
Cela permet d’obtenir rapidement des résultats impressionnants, mais masque aussi une partie importante des contraintes techniques réelles :
- consommation mémoire,
- temps de réponse,
- stabilité,
- gestion du contexte,
- ou encore limitations matérielles.
L’objectif de ce POC était justement de mieux comprendre ces problématiques dans un environnement maîtrisé.
Choix du modèle
Plusieurs modèles ont ainsi été testés localement au cours des expérimentations :
- Mistral,
- Llama 3, et 3.2
- Qwen 2.5 et 3.5
- DeepSeek R1,
- Gemma 3,
- Nomic Embed Text pour la génération des embeddings utilisés dans la recherche sémantique.
(Si le concept d’embeddings vous intéresse, je pourrai vous faire un article dédié.)
Les comportements observés étaient parfois très différents selon les usages.
Certains modèles semblaient relativement efficaces pour dialoguer ou reformuler une demande, mais beaucoup moins fiables lorsqu’il fallait sélectionner correctement un outil ou respecter un format précis.
La taille de ces modèles est volontaire limité pour tenir sur un pc et certains peuvent « halluciner » des réponses.
Même de simples ajustements de paramètres pouvaient fortement modifier le comportement global du système.
Le premier piège : le faux sentiment d’intelligence
Les premiers résultats obtenus étaient parfois étonnamment convaincants.
L’agent semblait capable :
- de comprendre certaines demandes,
- d’utiliser des outils,
- d’enchaîner plusieurs étapes,
- maintenir des conversations relativement cohérentes.
Par moments, l’ensemble donnait réellement l’impression d’un système capable de raisonner. Mais très rapidement, plusieurs comportements plus instables sont apparus. Par exemple, même lorsqu’un outil n’était pas nécessaire, l’agent cherchait parfois malgré tout à en utiliser un.
Dans d’autres cas :
- il sélectionnait un mauvais outil,
- interprétait mal le contexte,
- ou produisait des réponses plausibles… mais incorrectes.
Et lorsque ce système commence à interagir avec des outils ou des données réelles, cette illusion de maîtrise devient rapidement un sujet important.
Si votre agent n’appuie pas sur le bon bouton au bon moment, qui est responsable de l’action ?
Le moment où les prompts deviennent un problème
Au début du prototype, beaucoup de logique était directement dans les prompts, un peu à la manière d’interagir avec un chatbot..
Quelques règles ici. Quelques instructions là. Un peu de contexte supplémentaire.
Et soudain :
le système commence à devenir impossible à maintenir. Le moindre changement produit des effets de bord. Une phrase ajoutée pour améliorer un comportement peut en dégrader trois autres.
C’est à ce moment qu’une décision importante a été prise :
Aucun comportement métier , prompt ou choix de modèle ne devait être codé en dur. Les prompts, les outils, les paramètres et les règles devaient être externalisés.
L’objectif n’était pas seulement technique. Il s’agissait surtout d’éviter qu’un agent devienne une accumulation opaque de règles impossibles à comprendre. Ce choix a permis de supprimer les problèmes un par un.
De plus, finalement, le prompt ou le modèle ne sont pas si important dans la fabrication de l’agent. Cela sert surtout aux dernières optimisations.
Ce qu’il se passe réellement avant que l’agent réponde
Lorsqu’un utilisateur pose une question à un agent IA, la réponse n’est généralement pas produite immédiatement.
Avant d’obtenir une réponse finale, plusieurs étapes intermédiaires sont souvent nécessaires.
Dans le cadre de ce POC, le fonctionnement général reposait approximativement sur la chaîne suivante :
- réception de la demande utilisateur,
- analyse de l’intention,
- reconstruction éventuelle du contexte conversationnel (usage de la mémoire),
- recherche des outils potentiellement pertinents,
- sélection d’un outil,
- exécution de l’action,
- récupération du résultat,
- réinjection du résultat dans le contexte,
- puis génération de la réponse finale.
Sur le papier, cette logique paraît relativement simple.
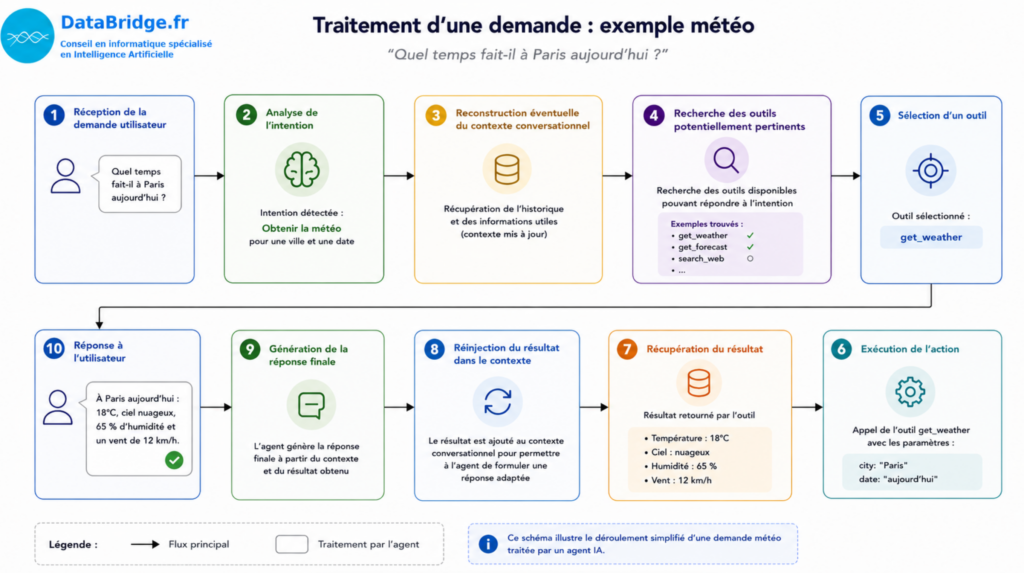
Mais dans la pratique, chaque étape peut devenir une source potentielle d’erreurs ou de comportements inattendus. Il est important de les découper en module distinct et indépendant afin de comprendre ou le modèle fait une erreur et comment changer la partie qui pose problème.
Un modèle très léger (par exemple: qwen2.5) peut suffire pour certaines tâches simples comme la reformulation, tandis qu’un modèle plus performant sera réservé aux étapes nécessitant davantage de raisonnement ou de génération de contenu. Cela permet une économie d’énergie, de coût pour une meilleur performance.
Très rapidement, on réalise donc qu’un agent IA n’est pas seulement un “modèle qui répond”. C’est surtout une chaîne d’orchestration dans laquelle chaque étape influence potentiellement toutes les autres.
Les différents outils mis à disposition de l’agent
Dans ce POC, l’agent ne disposait évidemment pas d’un accès libre au système.
Chaque action possible devait être définie à l’avance.
Autrement dit, l’agent ne pouvait agir qu’à travers certains outils mis à sa disposition.
Parmi les capacités disponibles, il pouvait par exemple :
- obtenir la date et l’heure,
- récupérer la météo pour une ville donnée,
- rechercher des informations sur internet,
- lire les fichiers d’un répertoire ou écrire dans un autre,
- interroger une base de connaissances,
- ou encore résumer un document.
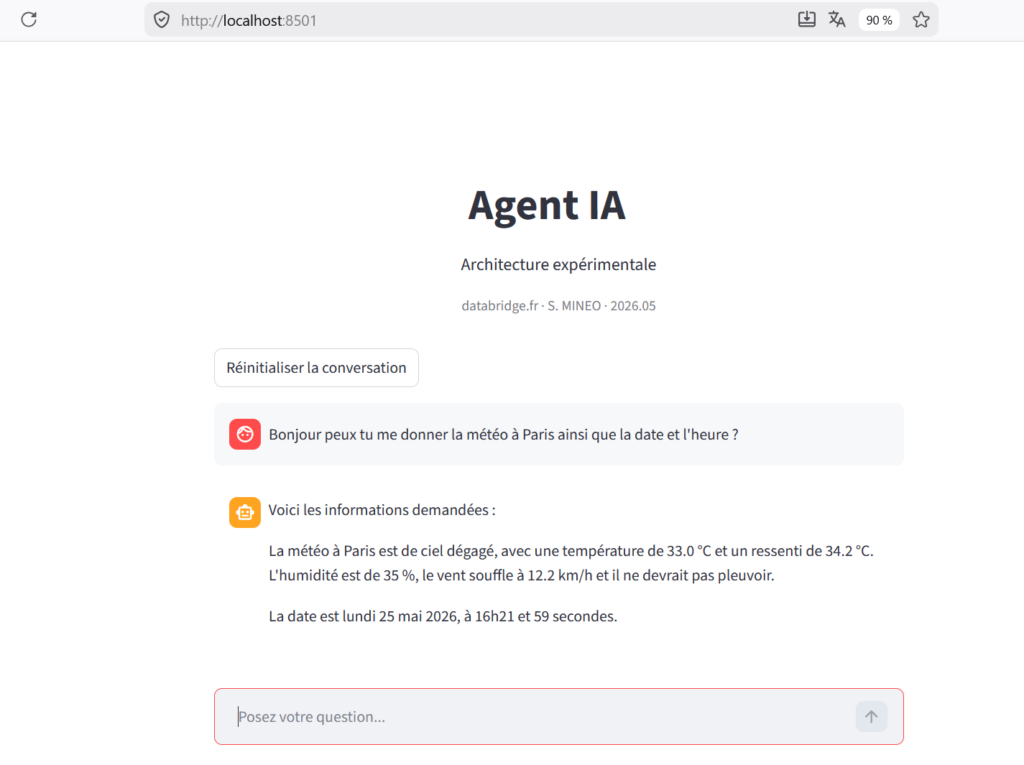
On peut finalement voir ces outils comme une série de boutons accessibles à l’agent selon les besoins.
Lorsqu’un utilisateur pose une question, le modèle tente alors de déterminer :
- s’il doit utiliser un outil,
- lequel semble le plus adapté,
- puis comment exploiter le résultat obtenu pour construire sa réponse.
Une grande partie du travail consiste donc à organiser correctement ces différents outils afin de rendre le comportement de l’agent le plus cohérent possible.
Une première vraie satisfaction
Après plusieurs ajustements et expérimentations, un moment particulièrement satisfaisant est finalement apparu :
celui où l’agent commence réellement à répondre comme attendu.
Les échanges devenaient plus naturels, les outils étaient correctement utilisés et certaines réponses donnaient enfin l’impression d’un système réellement utile.
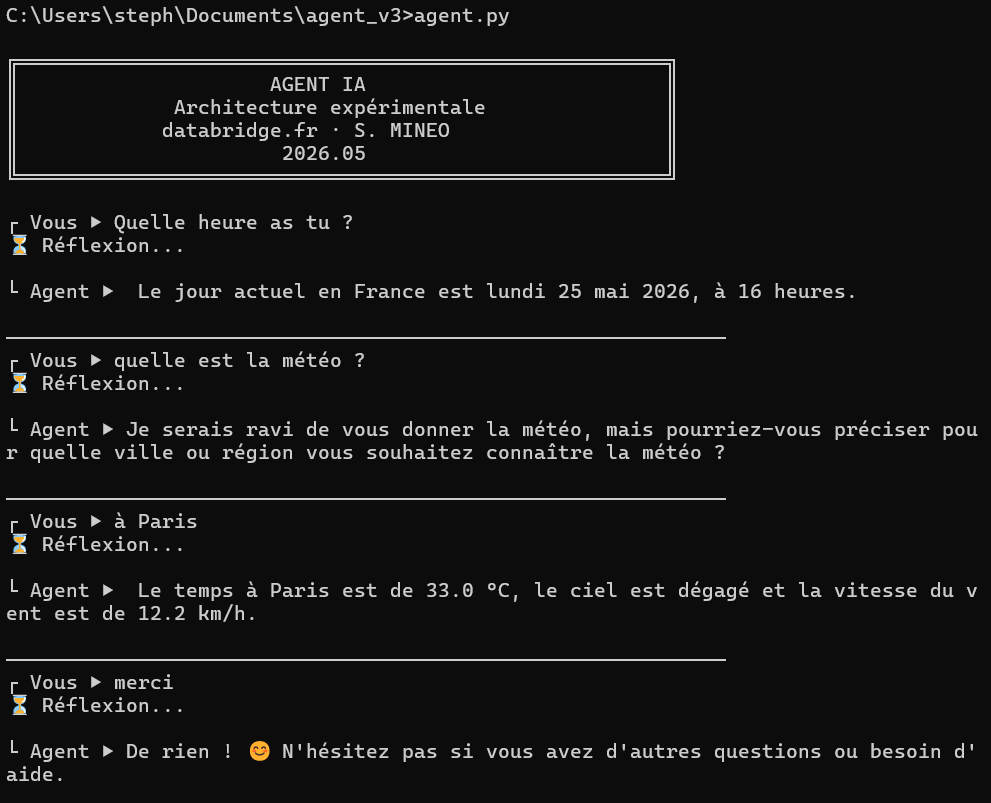
Même dans le cadre de ce simple POC, voir un agent :
- rechercher des informations,
- exploiter une base de connaissances,
- utiliser différents outils,
- puis construire une réponse cohérente,
reste particulièrement impressionnant.
Et surtout, cette architecture ouvre désormais la porte à une évolution progressive des capacités de l’agent.
Le prochain objectif sera d’ailleurs de lui permettre de générer lui-même certains nouveaux outils afin d’étendre progressivement ses possibilités, tout en conservant un cadre maîtrisé et sécurisé.
Et cette dernière partie sera un vrai défi…